
A Framework for a Secure Open-Source Software Supply Chain
A software supply chain where every component is transparent about its contents and its security status, and every application actively verifies its dependencies’ integrity in real-time.



Introduction
In late 2021, a critical vulnerability in the ubiquitous Log4j library (the Log4Shell incident) exposed thousands of applications to remote code execution attacks. Attackers wasted no time – at one point, over 10 million exploitation attempts per hour were observed. Perhaps more alarming, many organizations did not even realize they had this vulnerable open-source component in their software. This incident underscored a fundamental truth: modern software heavily relies on open-source dependencies, yet visibility into those dependencies’ security status is often lacking. With open-source components present in 97% of codebases on average, no organization is isolated from these supply chain risks.
Hidden Risks in the Open-Source Supply Chain
If a software application depends on an open-source library, that library is a Level 1 dependency. If that library in turn relies on another library, it creates a Level 2 dependency, and so on. In other words, dependencies form a multi-level web of packages – formally, a directed acyclic graph. Figure 1 illustrates a simple open-source dependency graph with direct and transitive dependencies.
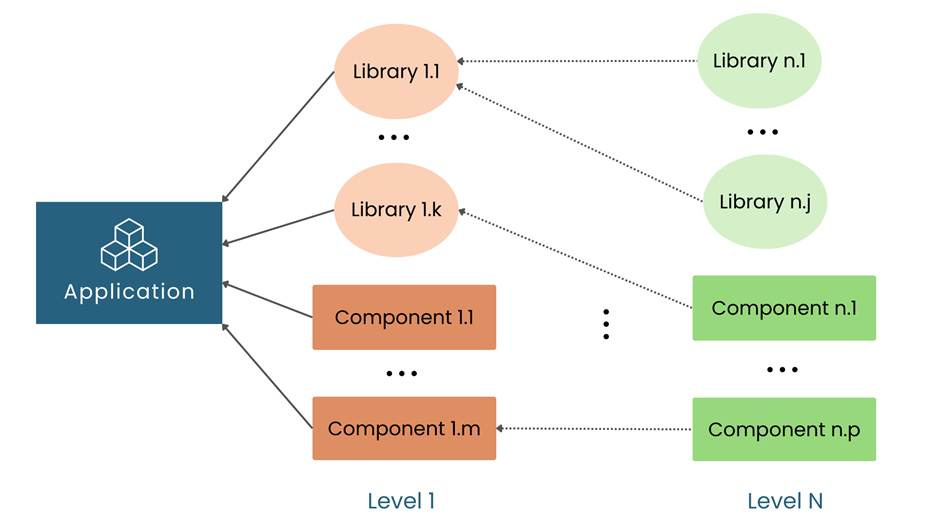
Figure 1: An example open-source dependency graph illustrating direct (Level 1) and transitive (Level 2+) dependencies in an application.
To make this more concrete, consider a real-world example: teable – a free, open-source no-code platform with a user-friendly interface (akin to Airtable) backed by a PostgreSQL database. Teable is built on Next.js (a React framework), which itself pulls in many libraries. Figure 2 shows a partial dependency graph for the teable that reveals dozens of libraries and sub-components.
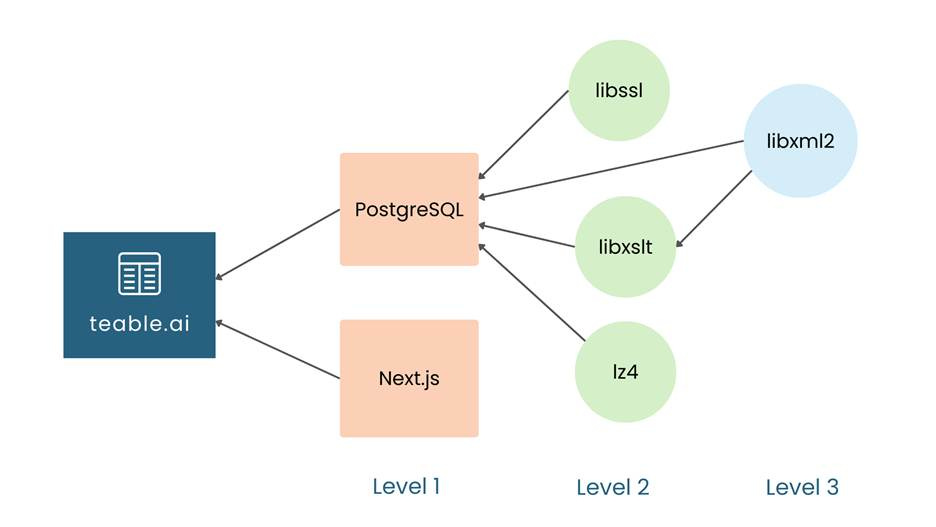
Figure 2: Partial dependency graph for the teable app.
Every single component (PostgreSQL, Next.js, libssl, libxslt, lz4, libxml2) in this graph has had security vulnerabilities reported within the past two years. This scenario is typical rather than exceptional.
According to the 2025 Open Source Security and Risk Analysis (OSSRA) report by Black Duck, each application has ~911 open-source components on average. This scenario of a multi-level web of direct and transitive dependencies is not a hypothetical one but is the norm. From a security perspective, such extensive use of OSS leads to two key issues:
Lack of visibility beyond the first dependency layer: Often, application owners do not know the complete list of nested dependencies their software relies on. As a result, they might miss critical security alerts or patches for deeper-level (Level 2, 3, …) libraries. For example, a vulnerability in a transitive dependency may go unnoticed until it’s exploited. Audits show 64% of open-source components in codebases are transitive dependencies, and nearly half of high-risk vulnerabilities are introduced via these deep, indirect components. Without complete visibility, such “hidden” vulnerabilities (like a Log4j buried in a third-party library) can lurk in software for long periods.
Delayed and manual security updates: If an application is installed as a pre-built package, its maintenance depends on the package provider’s update cycle. Security patches often get bundled with feature releases and are not delivered immediately. This means critical fixes may be delayed until the subsequent software version roll-out. Ideally, security updates should be decoupled and automated, rather than waiting for major releases. However, in practice, many organizations still update open-source components sporadically. This lag, coupled with the lack of visibility, leaves systems running known-vulnerable versions far too often.
Even organizations that develop critical applications in-house are not exempt. Co-author Ashwini Kumar Rath points out in his article that virtually every codebase includes some OSS. The 2025 OSSRA analysis found 97% of codebases contained open-source software (in specific tech sectors, this was 100%, with even the most conservative industries at 79%). From a security standpoint, 86% of codebases had at least one known OSS vulnerability, with a mean of ~154 vulnerabilities per codebase. These numbers make it clear that the open-source supply chain’s security blind spots are both widespread and severe.
A Two-Pronged Framework
In developing our solution, we were guided by two principles. First, a component in the software supply chain doesn’t know which downstream applications will use it, so it must publicly announce its current security and version information. Second, each application at runtime must verify that all components (at every dependency level) are using their latest, most secure versions, and report any exceptions to the user or an administrator. These principles ensure proactive transparency from component maintainers and continuous validation by applications.
Based on the above, we propose a solution with two complementary components:
Component 1: Auto-Generated Catalog for Visibility
Each open-source application, library, or component should maintain a Software Bill of Materials (SBOM) – essentially a complete inventory of its dependencies. The SBOM would list the component’s name and unique identifier, its version number, and references (e.g., repository or publisher URL). Crucially, this SBOM should be automatically generated at build time (as part of the CI/CD pipeline) to ensure it’s up-to-date for every release.
An SBOM serves as an X-ray of the software, revealing all the ingredients that make up an application. This includes not only direct dependencies but also transitive ones, providing complete visibility into the supply chain. Industry best practices now strongly advocate SBOM usage: for instance, the U.S. Executive Order 14028 (2021) mandates SBOMs for software sold to federal agencies, and NIST’s Secure Software Development Framework (SSDF) requires including SBOM information as part of secure development practices. Several SBOM standards have emerged – SPDX, CycloneDX, and SWID, among others – to define a standard structure and format for this inventory. Organizations can choose a format and use available tools (for example, Syft, CycloneDX plugins, etc.) to generate SBOMs automatically for their projects. The key is that every build produces a machine-readable list of precisely what components (and which versions) went into the software.
Having an SBOM for each component dramatically improves visibility. It allows developers and users alike to quickly answer: “What libraries (and which versions) does this software include?” In the context of our earlier example, if every application had an SBOM, companies would have immediately identified the presence of Log4j and its version in their systems, speeding up remediation. SBOMs also facilitate impact analysis for new vulnerabilities: when a new CVE is announced, organizations can search their SBOMs to see if they are affected. Experts now recommend maintaining an SBOM database and using automated tooling to cross-check for known vulnerabilities.
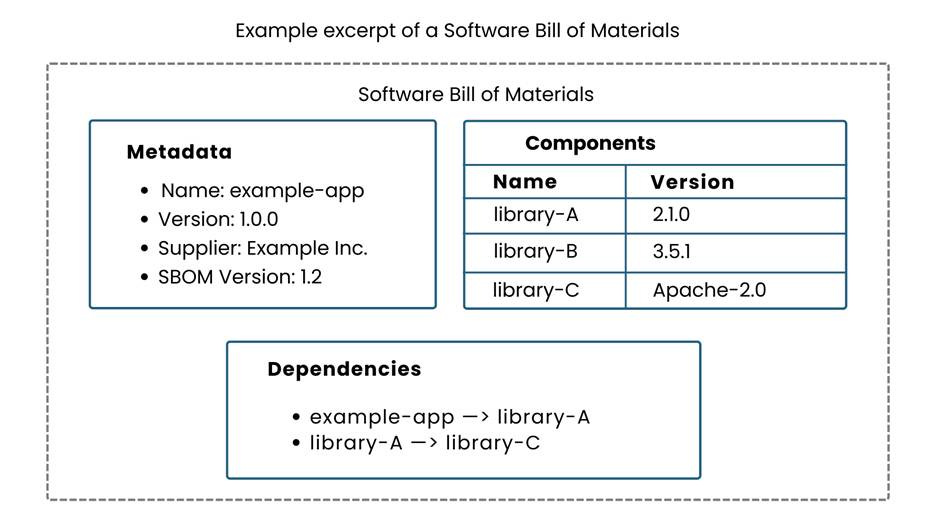
Figure 3: Example excerpt of a Software Bill of Materials. An SBOM enumerates an application’s components and their metadata (names, versions, licenses, etc.), providing a complete inventory of the software supply chain for that application.
Component 2: An Open API for Security Queries
In addition to the SBOM, each OSS project should provide an open API endpoint for machine-to-machine security queries. This would allow applications and tools to retrieve the latest security status of a component programmatically. For example, a library’s API could return information such as: “What is the latest version available? What vulnerabilities have been fixed in recent versions?” – in a structured format (e.g., JSON). By following a standardized interface (e.g., a RESTful API with an OpenAPI specification), this becomes a universal mechanism for software to ask its dependencies about their health. Notably, the Open Source Security Foundation is working on a “Security Insights” data standard to make project security info machine-readable in just this way.
The goal of this component is to automate updates and alerts. Instead of manually tracking mailing lists or release notes for dozens of libraries, an application can, at runtime, query each dependency’s API to check if a new, more secure version is available. If the API also provides details of security fixes (say, it lists recent CVEs addressed), the application can understand why an update is essential. This is similar in spirit to vulnerability feeds like VEX (Vulnerability Exploitability eXchange), which provide machine-readable advisories about whether a product is affected by a known vulnerability. The difference is that here each component actively publishes its current status for any consumer to retrieve on demand.
With Components 1 and 2 in place, the workflow would be as follows: each time an application starts (or on a scheduled interval), it loads its SBOM. It iteratively queries the security API of every library and component in its dependency graph. It then compares the reported “latest secure version” of each element to the version currently in use. If any component is out-of-date or has a known vulnerability, the application can generate a report or alert to notify the administrator or user. This check can be optimized (for example, performing it once daily in the background, even if the app runs continuously, to avoid excessive network calls). The result is continuous, automated monitoring of the entire open-source supply chain of an application.
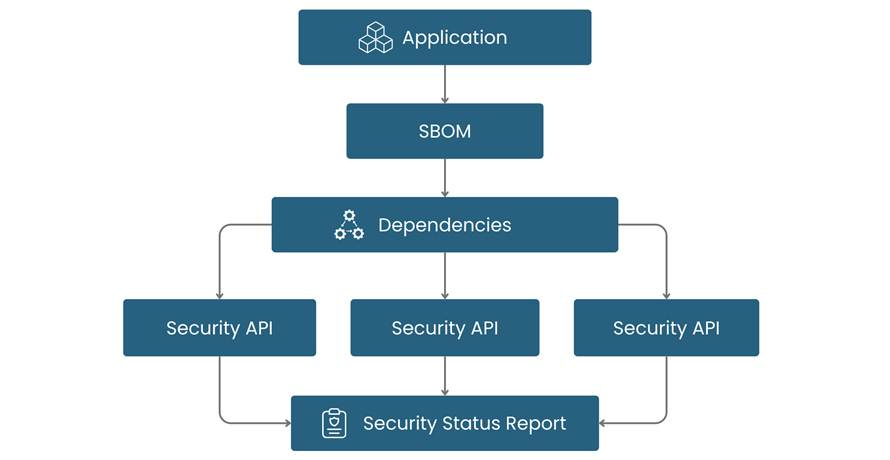
Figure 4: Illustration of an automated security query workflow. The application uses its SBOM to identify all dependencies, then queries each dependency’s security API for version and vulnerability info. The responses are aggregated into a security status report, alerting the user if any component is outdated or vulnerable.
Towards a More Secure Supply Chain
By combining SBOM-driven visibility with automated security queries, this framework addresses the twin problems of blind spots and slow updates in the open-source supply chain. The approach is aligned with emerging best practices and standards – from NIST’s SSDF guidelines emphasizing “Know Your Components” and prompt patching, to industry initiatives like OpenSSF’s efforts on Sigstore (for integrity through signed releases) and SLSA (Supply Chain Levels for Software Artifacts) for build provenance. In essence, we’re advocating for a supply chain where every component is transparent about its contents and its security status, and every application actively verifies its dependencies’ integrity in real-time.
Implementing this framework will require collaboration across the software community. Open-source maintainers would need to adopt standard SBOM generation and expose security query APIs (potentially with help from frameworks or hosting services to make this easier). Tooling will be key – for example, integration of these checks into package managers or CI pipelines would automate consumption of the SBOM and API data. Encouragingly, we see moves in this direction: automated dependency scanners and update bots (like Dependabot, etc.) hint at the benefits of machine-readable security info, and initiatives like OpenSSF Scorecards and Security Insights are laying the groundwork for it.
Going forward, adopting “secure by design” supply chain practices – maintaining an SBOM for every software, demanding SBOMs from vendors, and leveraging security APIs or data feeds – will be crucial to defend against the next wave of supply chain attacks. The open-source ecosystem’s strength is shared code; by equally sharing security information and responsibilities, we can ensure that this strength doesn’t become a single point of failure. Together, these measures form a robust framework that significantly raises the bar for open-source security in practice.
 | A guest post by
|
 | A guest post by
|